Gated Recurrent Units layer
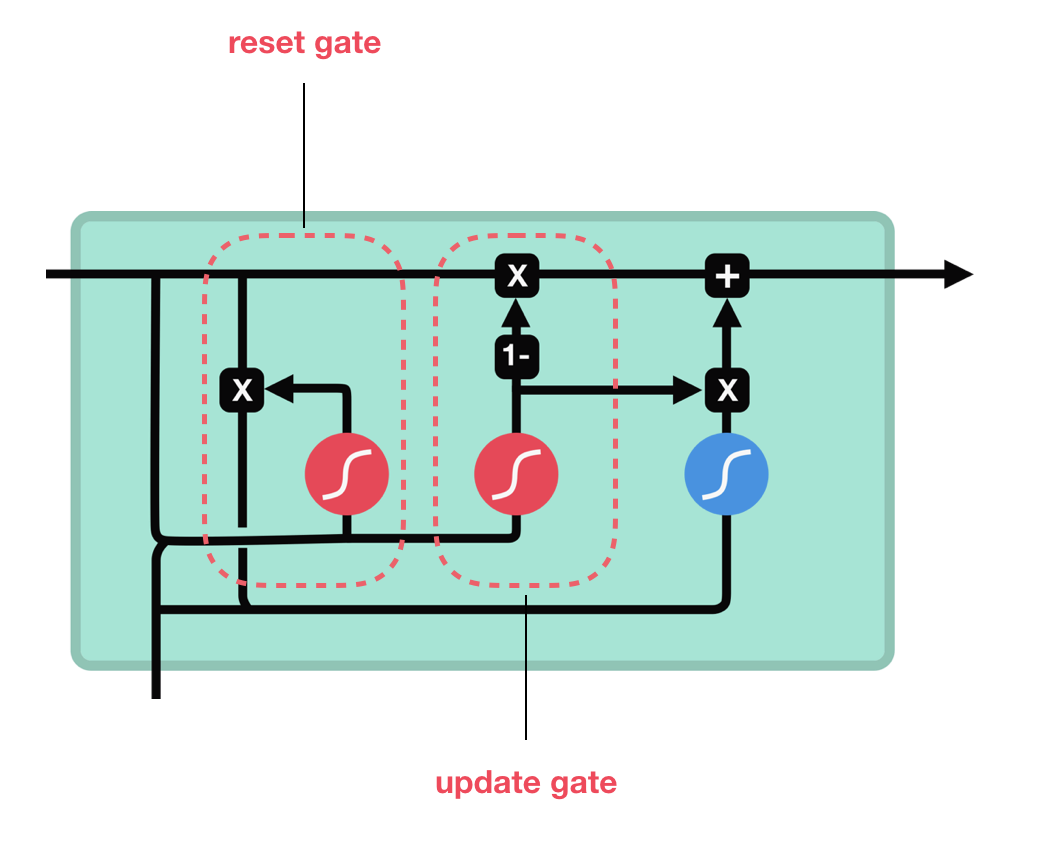
Presentation
This layer is a simple fully connected layer with Gated recurrent units instead of simple neurons. Gated recurrent units (GRUs) are improved version of standard recurrent neural network. The GRU is like a long short-term memory (LSTM) but with fewer parameters. This is really useful when predicting time series or classifying sequential data.
Declaration
This is the function used to declare a GRU layer.
template <class ... TOptimizer>
LayerModel GruLayer(int numberOfNeurons, TOptimizer ... optimizers);
Arguments
- numberOfNeurons: The number of neurons in the layer.
Here is an example of neural networks using a GRU layer.
StraightforwardNeuralNetwork neuralNetwork({
Input(1),
GRULayer(10),
FullyConnected(1)
});
See an example of GRU layer on dataset
Algorithms and References
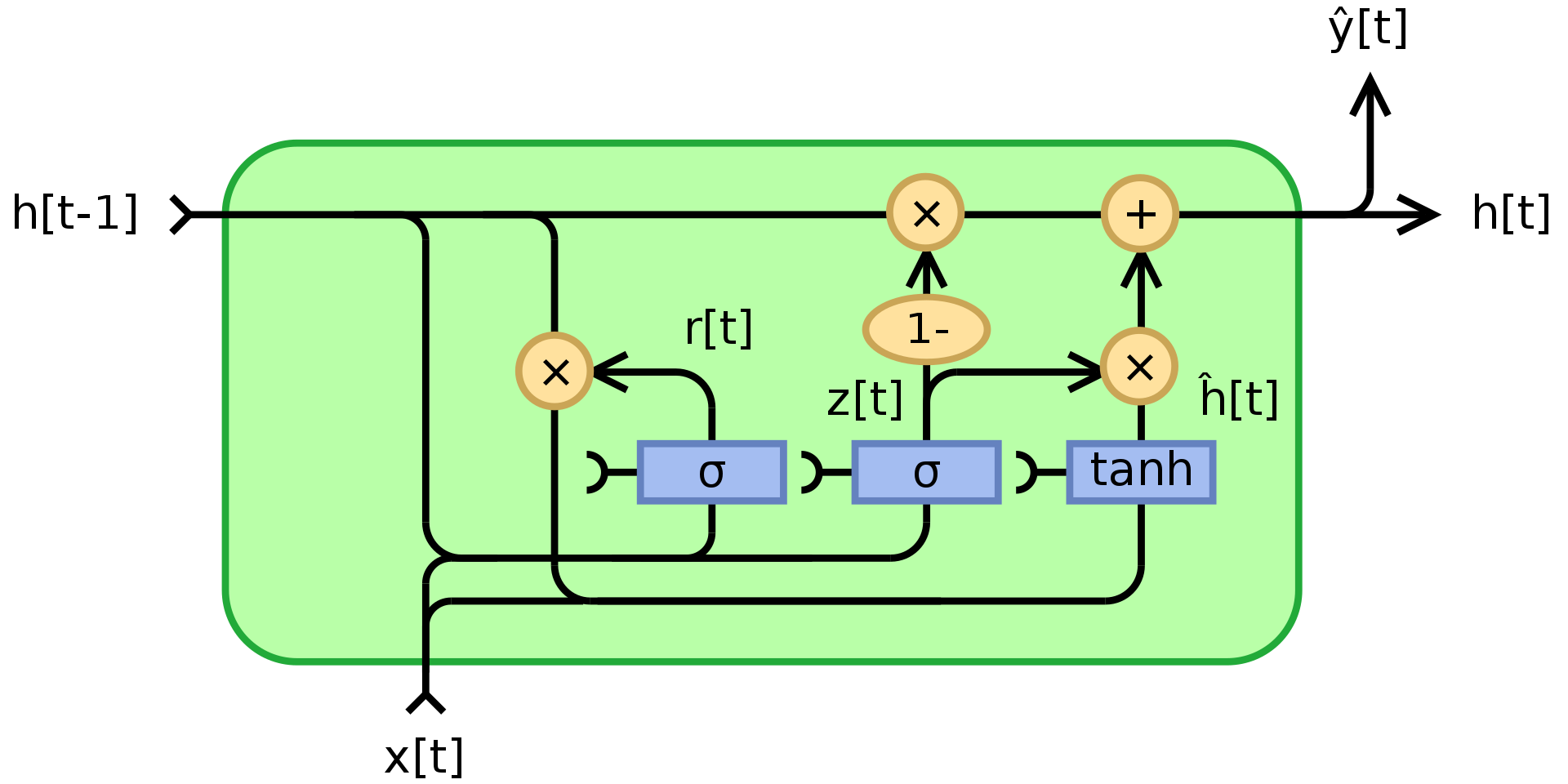
GRU implementation is based on Fully Gated Unit schema on Gated recurrent unit Wikipedia page. Also used Back propagation through time.